Edward Asiedu, MSc

Table of Contents
Federating cyber security data
Large enterprises are in a difficult position when it comes to data. They are contending with exploding data volumes. They operate in business with multiple incongruent cloud and SIEM applications. The quest has been on for liberation through effective security tools that scale affordably. From as long ago as 2016, IDC was spotlighting software architectures that rely on highly decoupled distributed systems[1]. In the IDC report, Five Benefits of Decoupling Compute and Storage for Big Data Deployments it was further noted that:
- Decoupling compute and storage is proving to be useful in big data deployments. It provides increased resource utilization, increased flexibility, and lower costs.
In the intervening years through to the time of writing (2024), this decoupling has been federated to the comparatively cheap, elastic compute and storage of the cloud. Cloud-based federation has been implemented both by long-established players like Splunk, and new services such as Hunters, Panther, Cribl, Anvilogic and DataBee, which define themselves in part by this decoupled, federated architecture.
A skim across each of the preceding products indicates that the idea of decoupling often has interpretations that vary by vendor. The resulting different implementations each have challenges associated with the respective product. In this article, the architectures are introduced, while a subsequent article will analyse the architectures and their associated challenges.
[1] Directions 2016 - Digital Transformation at Scale: Innovation in a Changed World. Hilwa (2016). IDC
Introducing the federation approaches
The central point of comparison for each federation approach is the data residency – whether the data received from disparate sources is centralised or siloed. Two other attributes distinguish the approaches, summarised in the table below:
| Federation Approach | Data Residency | Location of Queried Data | Data Schema Outcome |
|---|---|---|---|
| Close-Coupled | Centralised | Local | Normalised |
| Data-Fabric | Centralised | Remote | Matrixed |
| Inter-Platform | Remote | Remote | Fractionally Normalised |
| Reductive | Remote | Remote | Default State |
The following drawing shows the federation approaches and their attributes, organised around their data residency:
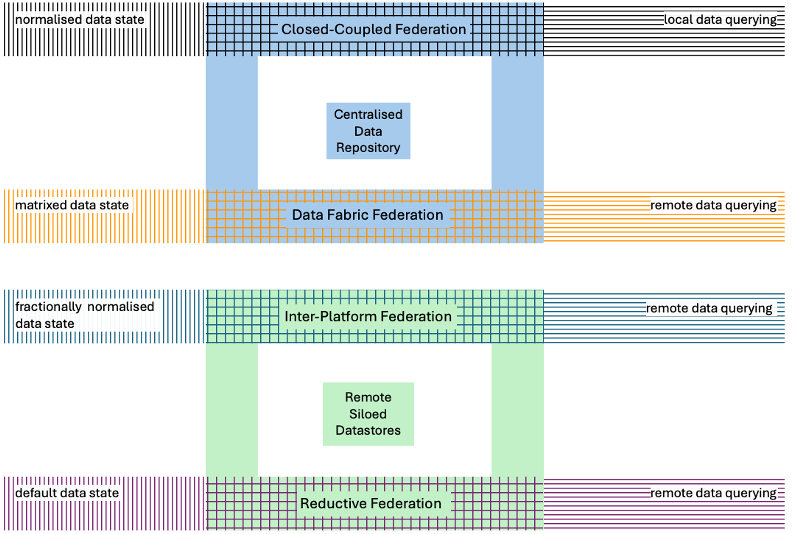
The diversity of the approaches is remarkable because vendors have incorporated the federation attributes quite differently, leading to clear dissimilarities in federation approaches and their associated solutions. It is worth noting too, that each vendor applying a particular form of federation believes that their approach works best for enterprises. The federation approaches are now explored in turn.
Close-Coupled federation
[centralised normalised data, localised for access]
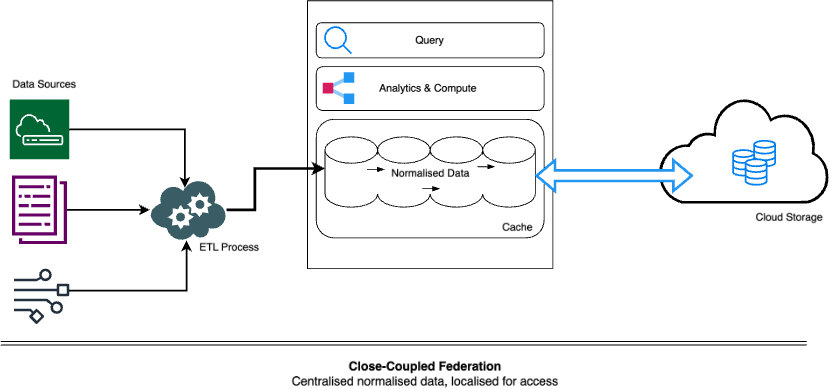
In this type of federation, the software often relies on traditional close-coupled hardware (i.e. memory, compute and storage that are (or perform like), they are locally attached. This aligns with critical design priorities, being the speed of querying, correlating and performing analytics on data from disparate sources. The fact that the data being queried is centralised, normalised and local to the compute resource facilitates true real-time receipt, querying and analytics of data.
Despite those benefits, decoupling becomes necessary because the storage for large volumes of security data, say from 1TB/day, becomes expensive when it is scaled proportionally with compute resources. So rather than having more units that combine both compute and storage, a separate elastic cloud storage stores long term data and feeds it to local storage as needed.
Data-Fabric federation
[centralised matrixed data, accessed remotely]
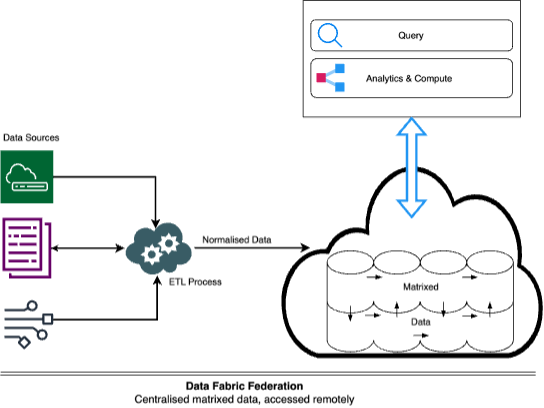
In this type of federation, data from various sources is centralised and normalised not only by IT domain (such as network and access management), but also between IT and business domains to create a matrix of highly correlated data for comprehensive query results. The federation of this data occurs by storing it in a data lake, where storage will expand independently of compute. Unlike in close-coupled federation, the software is often microservices-based, and the data lake is remote, eliminating the simultaneous increase of compute costs with storage.
Here, the appeal is from correlation and re-usability of the centralised data by different consumers across the enterprise, including for continuous controls monitoring. This architecture overcomes storage capacity limitations of close-coupled federations.
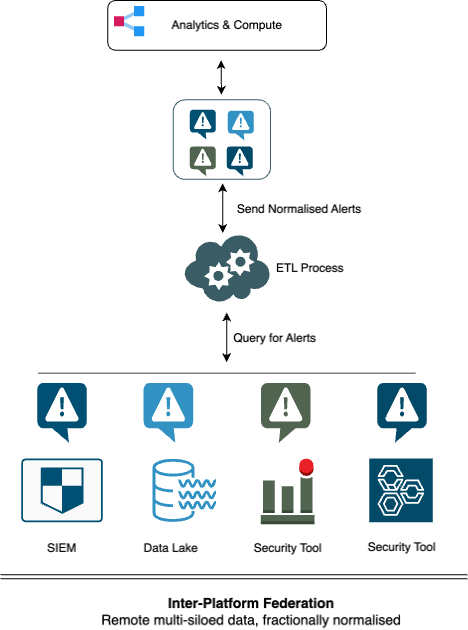
Inter-Platform federation
[remote multi-siloed data, fractionally normalised]
In this type of federation, a central layer is designed as the single place to query multiple data repositories such as data lakes, cloud storage and SIEMs. Quite importantly, the data remains in place at these locations, while the results of queries (typically alerts) are sent to the central layer. When the results are received, they are normalised into a consistent format for further actions in the central layer. This approach has easy adoption appeal because it effectively leaves federation to customers by treating their customer’s existing data repositories as federated storage.
Reductive federation
[remote multi-siloed data, accessed in its default state]
This type of federation shares much in common with Inter-Platform Federation. Again, a central layer is designed as the single place to query multiple data repositories. In contrast, the design does not include normalising all results of a query. As the name implies, this approach is often implemented within a data volume reduction strategy, where data from various sources is fed through a size-reducing processor while in transit to any number of repositories. Oftentimes, that data is stripped, aggregated or sampled. The data reduction is often to limit the volume received by a close-coupled system.
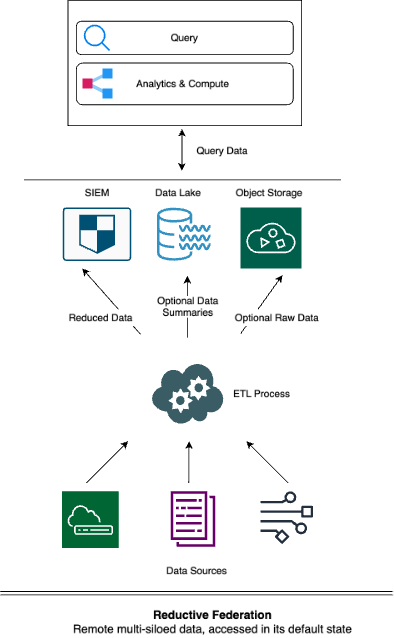
This approach also has appeal, for two reasons:
- the opportunity to reduce the cost of owning a close-coupled system by drastically reducing the amount of data stored in that more expensive architecture, sometimes saving a small fortune
- getting away with said cost reduction
Conclusion
Data federation is a part of many ostensible solutions for addressing the data volume explosion, but the various incarnations of the federation are imperfect. This article introduced four federation approaches seen across different vendors. A subsequent article will explore drawbacks to each architecture, and the corresponding consequences that need management.
Continue Reading: Minding the stepping stones across security data silos
