Edward Asiedu, MSc

The drawing below is a simplified version of the typical data morass that large organisations face, composed of sources spanning on-premises data, multi-cloud data and (I/P/S/C)-as-a-service.
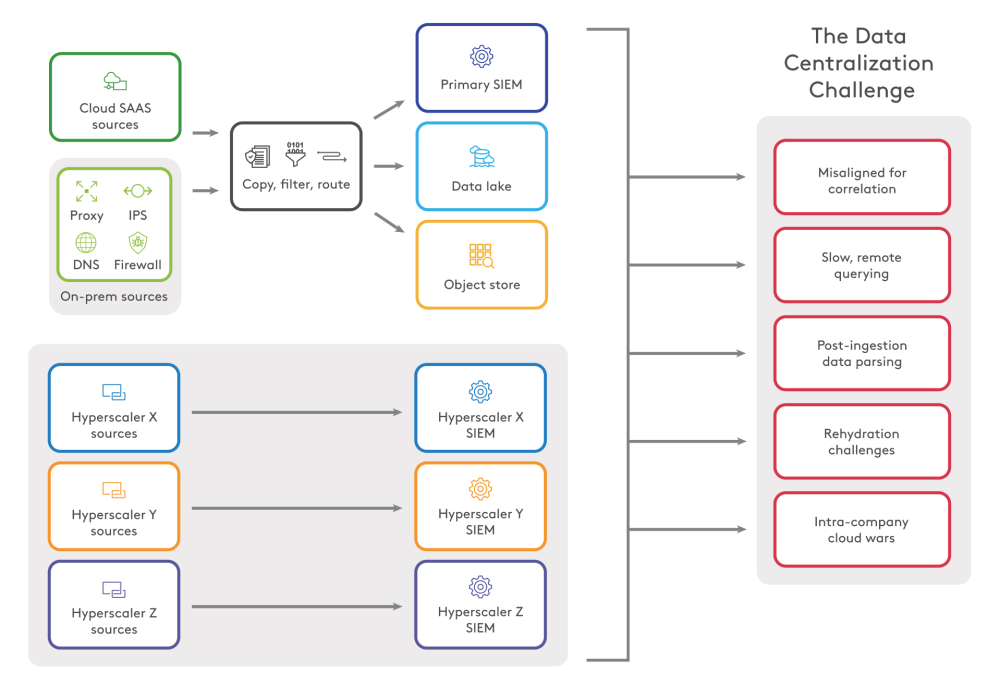
This is such a fractured state of affairs, that it prompts a few questions:
- Have information security departments given up on centralising cybersecurity data?
- Why did organisations ever try?
- How could any organisation succeed at centralising security data today?
Why centralise security data?
Let’s start by answering the easiest of three questions first – the why: many security standards specify controls where event logs from multiple security tools are centralised for analysis and correlation, for example in a SIEM.[1] While the SIEM acronym may be out of favour with some readers, the concept of “Security Information and Event Management” is indisputably essential for large, digitised organisations. One should emphasise the management part of the concept, which has fallen off more recent acronyms. For those who prefer the cybersecurity mesh concept, it too, has a centralised security data layer.[2]
In any case, the successful execution of the SIEM concept is as important as ever, regardless of which acronyms and labels are thrown around. We hear that the latest security data product named with three/four capital letters is “next-gen”, “intelligent”, “cloud native”, “AI-first”, et cetera, while the others are “legacy” technologies. Regardless of the year that a SIEM-concept product was first marketed, the insidious legacy aspect that plagues many of these is the paradigm of siloing that applies to security data:
- intra-company silos – oftentimes, the SOC and SIEM are the only designated consumers of security data, while willingness and capability for sharing the data are lacking[3]
- vendor silos – data mobility[4]and interoperability are often costly or tedious to attain
Now that we have discussed a couple of motivations and challenges related to centralising cybersecurity data, we can begin to answer all the earlier questions in the context of data residency and organisational capability.
Are information security departments succeeding in centralising cybersecurity data?
As long ago as 2013, a SIEM was considered table stakes (the minimum outlay) for organisations wanting to build an advanced cybersecurity capability. At the time, analysis and correlation were applied to detect threats across event streams from internal infrastructure such as network traffic, email, and server logs.[5] In that context, collecting events, perhaps for an on-premises SIEM, was a relatively finite and achievable task. However, through the present time, as organisations undergo digital transformation and migrate operations to the cloud, it has re-emerged as a challenge to integrate and centralise event streams from infrastructure, cloud, and software-as-a-service platforms.[6]
The problem is not merely that data is siloed – it’s that organisational cybersecurity responsibility is centralised, as is the risk to the organisation’s balance sheet and stakeholders[7], whilst conversely, fragmented data prevents organisational knowledge of consolidated security risk exposure. This fragmented data can look like a sea of seemingly disconnected activities. However, to proactively reduce risk, organisations must try to identify relationships between activities before they have an impact.[8]
Nonetheless, security offices are contending with high rates of data output, large varieties of data sources, and incongruent data structures. These all make it difficult to assemble an integrated understanding from the limited vantage points of each source’s dataset. It’s unsurprising then, that despite the potential blind spots, some vendors and security offices are leaving data in their respective silos. Examples of such siloed architectures are Inter-Platform Federation and Reductive Federation, which overlay remote, fragmented cyber data. Those architectures are however accompanied by additional daily operational difficulties such as latency and uncorrelatable data.[9]
So, for security offices that are seeking centralised cybersecurity data, what is a solution? Historically, the answer would have been a SIEM, just by itself. Unfortunately, SIEMs from many vendors have architectural challenges that persist even when the SIEM federates to the cloud in a Close-Coupled architecture. Despite the challenges, for many organisations, a quality SIEM still has certain speed and usability advantages that many purported replacements do not. For example, it is reasonable for security analysts to experience “real-time” receipt and querying of data when that is promised by a product. Another example is where the SIEM alternative requires navigating, converting, and joining SQL table elements, which SOC analysts can experience as time-sapping obstacles to answering urgent, ad hoc questions emerging from investigations.
Many organisations seek workarounds for scaling and retention constraints that they may experience with their primary SIEM. One workaround is to reduce the SIEM workload and maintain its speed by prioritising certain data sources for analytics and limiting their retention. As illustrated earlier, this is supplemented by storing data the organisation would like to retain in one or more of:
- a secondary SIEM (where query speed and latency are lower priorities)
- an object store
- a data lake (or warehouse, or lake-house, etc.)
The data offloads evidently do not centralise security data and they may perpetuate SOC-centric ownership of security data, when the organisation would be more resilient if, for instance, the compliance function could leverage aspects of the same data. Consider a governance risk and compliance (GRC) function enabled with the data to continuously monitor security controls like secure configuration and vulnerability management. GRC can in turn work with IT and relevant leaders to reduce the likelihood of incidents for which a SOC is needed.[10]
How could any organisation succeed at centralising security data today?
Consider an organisation which centralises some cyber data that is a year old or newer in a SIEM - how could it centralise the remaining data cost-effectively without introducing another silo? The simple version of the answer is to augment the SIEM, but with what? A subordinate data layer that helps cost-effectively address the retention and scalability issues, while maintaining correlation and analytics capability. Fortunately, technology like this already exists, but in the following table, let’s summarise the solution requirements first.
| Requirement | Effect |
|---|---|
| Addressing retention and scalability issues | Scaling elastically in the cloud to receive high throughput data and store long-retained data, even for many years. Implemented through a decoupled architecture that facilitates storage growth without driving compute costs simultaneously. Achieved at the cost of the latency associated with the decoupled storage layer. |
| Maintaining correlation and analytics capability | Rather than serving as a dumping ground for raw data in its default state, can ingest and transform received data to a suitable schema. Analytical, machine-learning and other processes can be applied to the data for insights. |
| Subordinate data layer | Avoids creating another screen to pivot to for context. Instead, security findings from correlation and analytics are pushed to the SIEM with supporting raw data. This enables the SIEM to present findings of the subordinate data layer as though the SIEM processed the data, and avoids creation of another silo. |
One could simply call this a SIEM augmentation layer. An incarnation of this is a Data Fabric Federation architecture9. Here is what the SIEM augmentation and data relationships could look like.
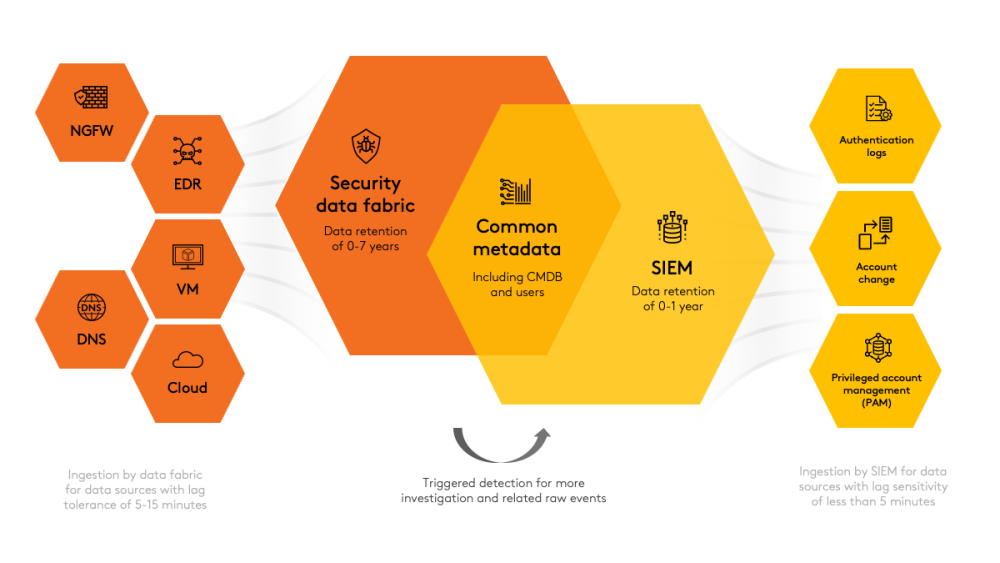
This architecture achieves a few goals:
- For data sources excluded from SIEM ingestion due to cost trade-offs, recovering their value by correlating the full scope of security-relevant activity.
- Centralising the data without producing another silo, which not only avoids disruption to existing security operations workflows, but enhances the intelligence available to them.
- The data fabric facilitates tailoring of security data products for AI, machine learning and security governance risk and compliance. This is the “multi-consumer” vision of an enterprise data mesh, the organisational model used to manage data products.[11]
Conclusion
Organisations have made the business decision to adopt distributed architectures across networks and the cloud. Those decisions renewed the challenge of centralising cybersecurity data, where in response, some organisations are looking to a data mesh approach to produce data products on top of data fabric architectures. This article discussed the practicality of this method to expand the data sources and retention available for enterprise cybersecurity operations, while simultaneously empowering GRC and other teams to act proactively in reducing cyber risk.
[1] See for example, NIST 800-53 rev 5 Controls AU-2, AU-6, PL-9; CIS Control 8; ISO 27002 Control 12.4
[2] Ramos-Cruz, B., Andreu-Perez, J., & Martínez, L. (2024). The cybersecurity mesh: A comprehensive survey of involved artificial intelligence methods, cryptographic protocols and challenges for future research. Neurocomputing, 581, 127427.
Gartner. (2024). Cybersecurity Mesh.
[3] Goasduff, L. (2021, May). Data Sharing Is a Business Necessity to Accelerate Digital Business.
[4] Sommerfeld, B., Elbekry, A., & Ene, L. (2015, October). Inside: CIO Edition by Deloitte.
[5] Deloitte. (2013). Tech Trends 2013 - Elements of postdigital.
[6] McKinsey & Company. (2020). Cybersecurity in a Digital Era.
[7] Maze, T., & Musselwhite, D. (2020, May 19). Primary vs. Secondary Loss in FAIRTM Analysis: What’s the Difference and Why It Matters.
[8] Howard, R. & Olson, R. (2020). Implementing Intrusion Kill Chain Strategies. The Cyber Defense Review. 5(3), pp.59–76
[9] Asiedu, E. (2024). Four ways of federating exploding cyber data.
[10] Abdillahi, Y. (2024). The Rise of Cybersecurity GRC. Corporate Compliance Insights.
[11] Beyer, M., & Thanaraj, R. (2024). Data Mesh v/s Data Fabric? Identify the Benefits and Risks Before Making Your Decisive 2024 Investment. Gartner Data & Analytics Summit.
